
Normal Distribution Basics
The purpose of this post is to explain some basics of the Normal Distribution. In furture posts I will be explaining the Auto-Regressive (AR) model and the concepts explained here will be important for understanding it.
Normal Distribution
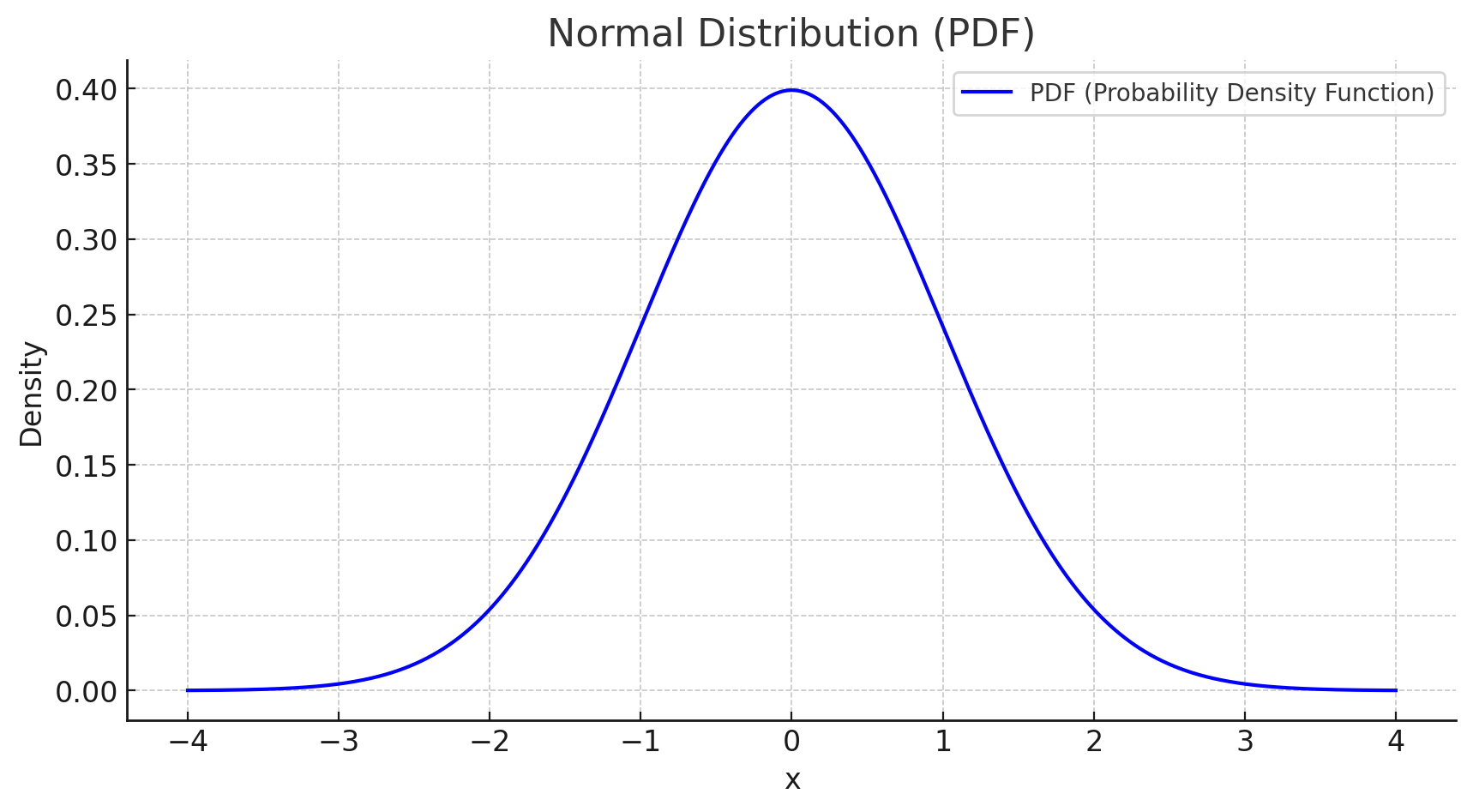
The normal distribution (also known as the Gaussian distribution) is a continuous probability distribution that describes data clustering around a central mean. It has a characteristic bell-shaped curve that is symmetric about the mean.
The probability density function (PDF) of a normal distribution is given by:
\[ f(x) = \frac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x - \mu)^2}{2\sigma^2}} \]
- \( \mu \) is the mean (center of the distribution).
- \( \sigma \) is the standard deviation (spread of the distribution).
- \( \sigma^2 \) is the variance (measure of dispersion).
Key Properties
The normal distribution follows the 68-95-99.7 Rule:
- 68% of values lie within 1 standard deviation (\( \mu \pm \sigma \)).
- 95% of values lie within 2 standard deviations (\( \mu \pm 2\sigma \)).
- 99.7% of values lie within 3 standard deviations (\( \mu \pm 3\sigma \)).
Probability Density Function (PDF) Plot
Cumulative Distribution Function (CDF)
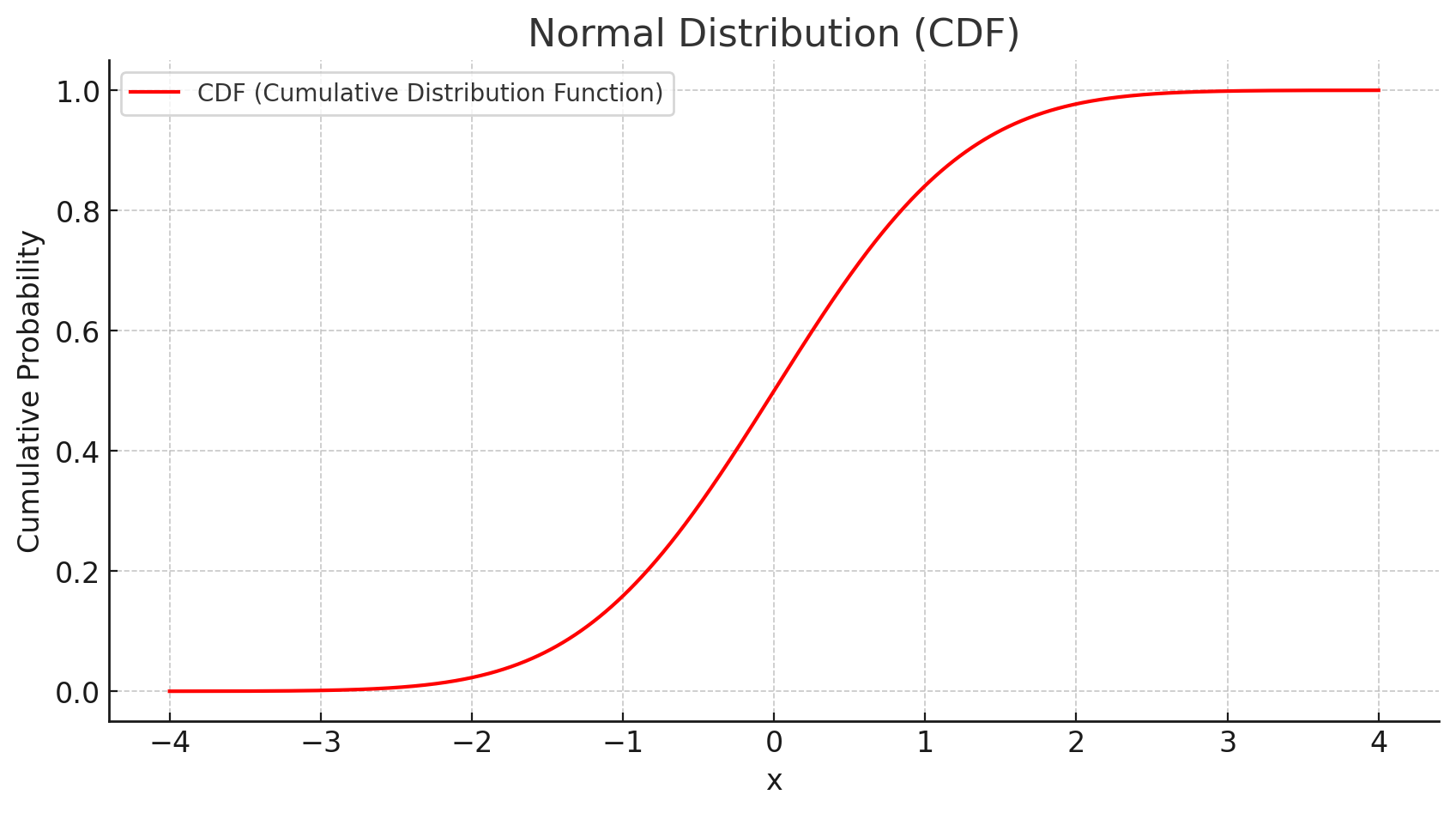
The cumulative distribution function (CDF) gives the probability that a random variable \( X \) is less than or equal to a specific value \( x \):
\[ F(x) = P(X \leq x) = \frac{1}{2} \left[1 + \operatorname{erf} \left( \frac{x - \mu}{\sigma \sqrt{2}} \right) \right] \]
where \( \operatorname{erf}(z) \) is the error function, a special function that cannot be expressed in elementary form but is available in most mathematical libraries.
Cumulative Distribution Function (CDF) Plot
Applications of the Normal Distribution
- Hypothesis testing (e.g., Z-tests).
- Confidence intervals in statistics.
- Machine learning (e.g., Gaussian Naive Bayes, Gaussian Processes).
- Signal processing and error modeling.
Understanding the normal distribution is essential for many fields, including statistics, finance, and engineering. Its applications range from modeling real-world data to improving machine learning algorithms.